LLM Inference 简述
2023年10月28日 · 1559 字 · 4 分钟 · LLM
LLM Parameters
LLM 中的每个 Transformer 包括 self-attn block 和 MLP block,总参数量为 $12h^2+13h$。如果 LLM 有 $l$ layers, 包括 embedding 一起算,总参数量为 $l(12h^2+13h)+Vh$。同时,对于一个 $l$ layers 的 LLM,FLOPs 为 $l(24bsh^2+4bs^2h)+2bshV$ (没有计算 Softmax 和 LN 等过程)。
| Parts | Modules | Parameters | FLOPs |
|---|---|---|---|
| self-attn block | $W_{K}, W_V, W_Q, W_O, \text{LayerNorm}$ | $4h^2+6h$ | $8bsh^2+4bs^2h$ |
| MLP block | $W_1,W_2,\text{LayerNorm}$ | $8h^2+7h$ | $16bsh^2$ |
在训练的时候一般采用 AdamW optimizer,利用混合精度,为 FP32 的权重存储 FP16 格式。虽然这样多存了一份权重,但使用 FP16 计算 intermediate activations 通常能大大减少显存使用。所以,总的显存使用量往往仍然比纯 FP32 训练要小。考虑到 AdamW 会保存 FP32 的一阶动量和二阶动量,对于每个可训练参数来说,需要显存大小如下:
$$ [\text{weights}](2+4)+[\text{gradients}](2+4)+[\text{optim}](4+4)=20 \text{ bytes} $$
注:计算 gradients 的时候可以把 FP16 释放,所以一些论文写的是 18 bytes 。
我们可以近似认为:在一次前向传递中,对于每个 token,每个模型参数,需要进行两次浮点数运算,即一次乘法法运算和一次加法运算。每次 backprop 的计算量是前向传递的两倍,所以是四次,加起来是六次。如果考虑激活重计算技术来减少中间激活显存,需要进行八次。在给定训练tokens数、硬件环境配置的情况下,训练transformer模型的计算时间为: $$ \text{Training Time} = \frac{8\times s \times \text{Model Params}}{\text{num of GPUs} \times \text{Peak FLOPs} \times \text{GPU-Util}} $$ 注:随着 batch size 的增大,中间激活占用的显存远远超过了模型参数显存。通常会采用激活重计算技术来减少中间激活,理论上可以将中间激活显存从 $O(n)$ 减少到 $O(\sqrt{n})$,代价是增加了一次额外前向计算的时间,时间换空间。
因为少了梯度、优化器状态、中间激活,模型推理阶段占用的显存要远小于训练阶段,只包括了模型的权重大小和用来加速推理的 KV cache 。比如,如果不考虑 KV cache,对于一个 7B 的 model,用 FP16 推理,大概需要 14 GB 的显存。
KV cache
LLM inference 的时候,可以利用 KV cache 以 memory resource 换 computation resource,可以每次只inference 一个 word 出来。假设刚开始的 prompt shape 是 $[b, s, h]$, 得到 K, V, Q 的 shape 是 $[b,n,s,h/n]$,最后 output 的 shape 也是 $[b, s, h]$。后面 word 挨个 feed 进去 (seq_len=1),保留前面的 KV 信息。此时 input shape 是 $[b, 1, h]$,计算 self-attn 的时候把 KV concat,他们的 shape 变成了 $[b,n,s+1,h/n]$,而Q 的shape 则是 $[b,n,1,h/n]$。最后输出是 $[b, 1, h]$,decode 后就是一个 word 。
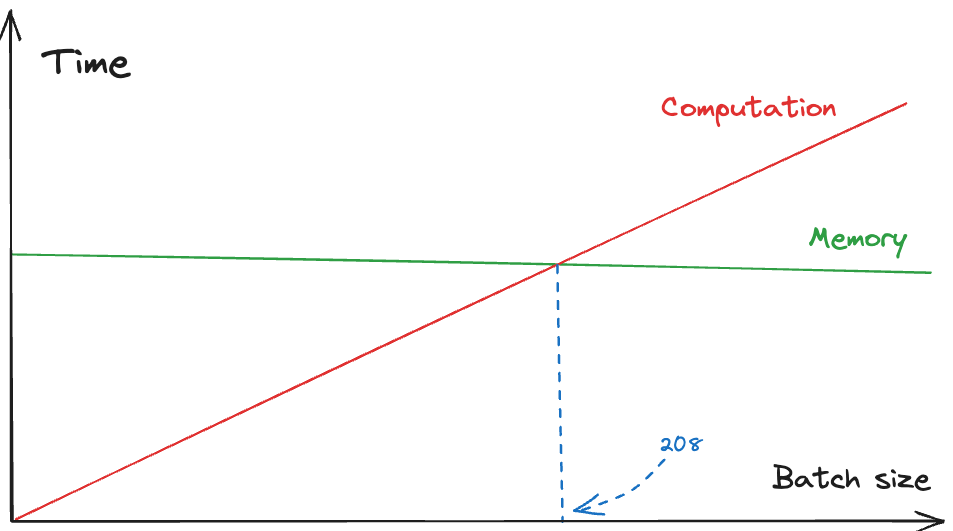
每个 token 所存储的字节数为(第一个 2 是有 KV 两个要存,第二个 2 是假设了数据类型为 FP16,需要两个字节,所以 past KV 的 shape 为 $[b, 2, n,s,h/n]$): $$ 2 \times 2 \times n_{\text{layer}} \times n_{\text{head}} \times \frac{h}{n_{\text{head}}} $$ 对于一个 $n_{\text{layer}}=64, h=8192$ 的 model 来说,按照 FP16,一个 token 的 KV cache 要占用大概 $4\times 64\times 8192\approx 0.002GB$,1000 个 token 的 KV cache 就 2GB 了,还是挺多的。此时,计算一个 token 的 KV 所需的 Flops 为: $$ 2\times 2 \times n_{\text{layer}} \times h^2 $$ 对于 A100 来说(312e12 flops/s and 1.5e12 bytes/s of memory bandwidth),计算一个 token KV 所花的时间和为了计算 KV我们需要加载权重 $W_{k}, W_v$ 所花的时间为 $$ \text{Computation} = 4n_{\text{layer}}h^2/312e12 $$
$$ \text{Memory} = 4n_{\text{layer}}h^2/1.5e12 $$
显然,Memory 要花 208 倍的时间,如果我们要计算一个 token 的 KV,和计算 208 个 token 的 KV 花的时间是一样的。
- 如果我们计算的 token 数小于 208,就会受到 memory bandwidth bound
- 如果我们计算的 token 数大于 208,就会受到计算 flops bound
每个 transformer 层的总参数为 $12h^2+13h$,除了 KV 计算的其他部分也依照这个 208 的 rule。注意,我们必须提高 batch size,否则是不划算的,会受到 memory bound,还不如直接计算。
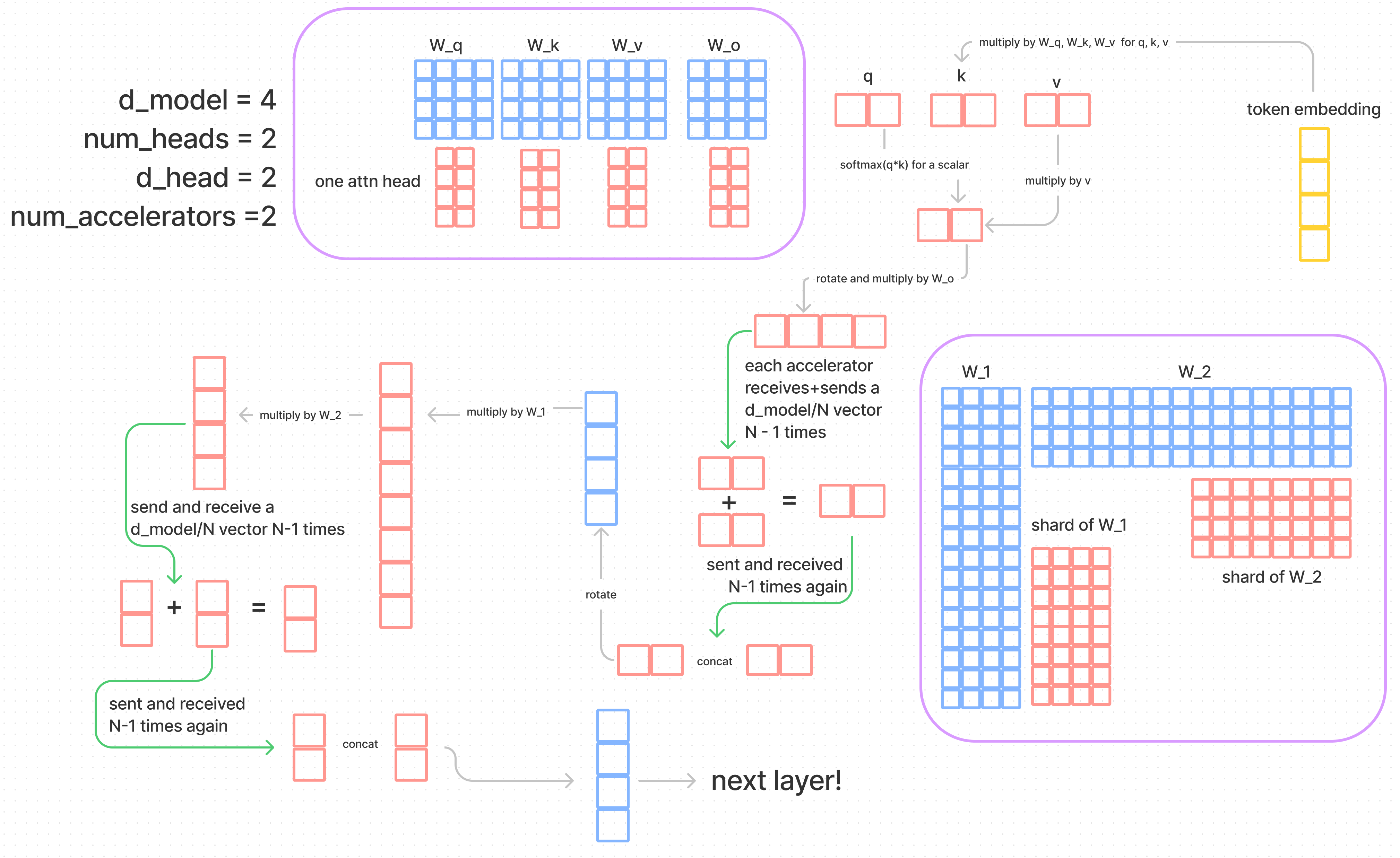
Model Parallelism
Model Parallelism 包括了 tensor parallel 和 pipeline parallel 。tensor parallel 在模型的中间split,每个 GPU 将权重分片推理。pipeline parallel 是每个 GPU host 一些完整的层,pipeline 在 inference 的时候会出现问题,每次只有一个 GPU 在 working。 pipeline parallel 的好处就是减少了 communication,因为每个 GPU 只要和下一个 GPU communicate 就好了,model parallel 则是全部都要一起 communicate 。对于每个 GPU,需要 communicate 的数据量为 $4(N-1)h/N$。下图是 Kipp blog 中用的一幅图,我就偷过来直接用 XD。