Pytorch Basics
Table of Contents
01. Overview
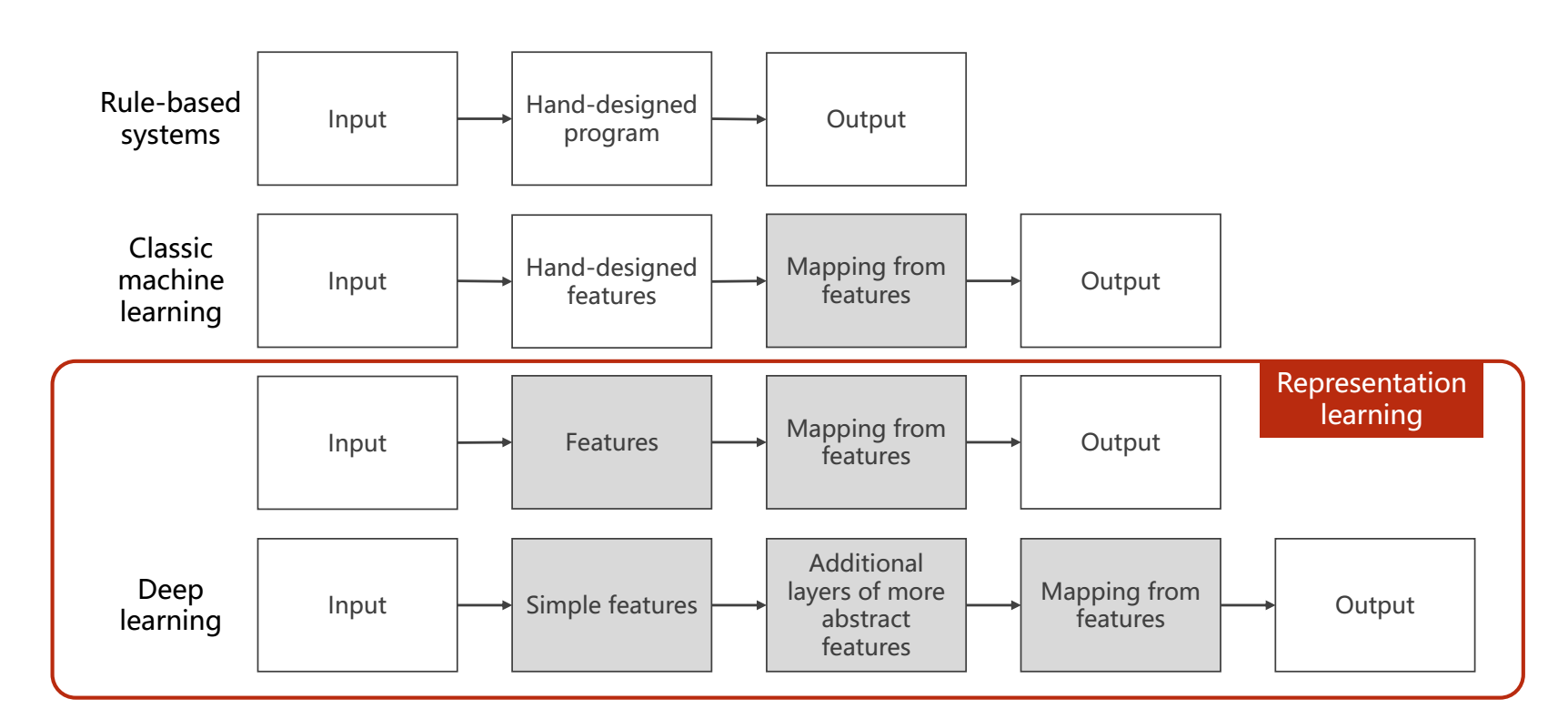
DL & ML
- 维度诅咒:维度越高,需要的训练集越大
- 深度学习和机器学习的区别:多了一层用来提取特征的层。传统的机器学习中(无标签),Feature是单独做训练的,后面的Mapping from features和它是分开的。但是在深度学习中,这个是统一的。所以深度学习也称为 End to End 的学习方式。
Route
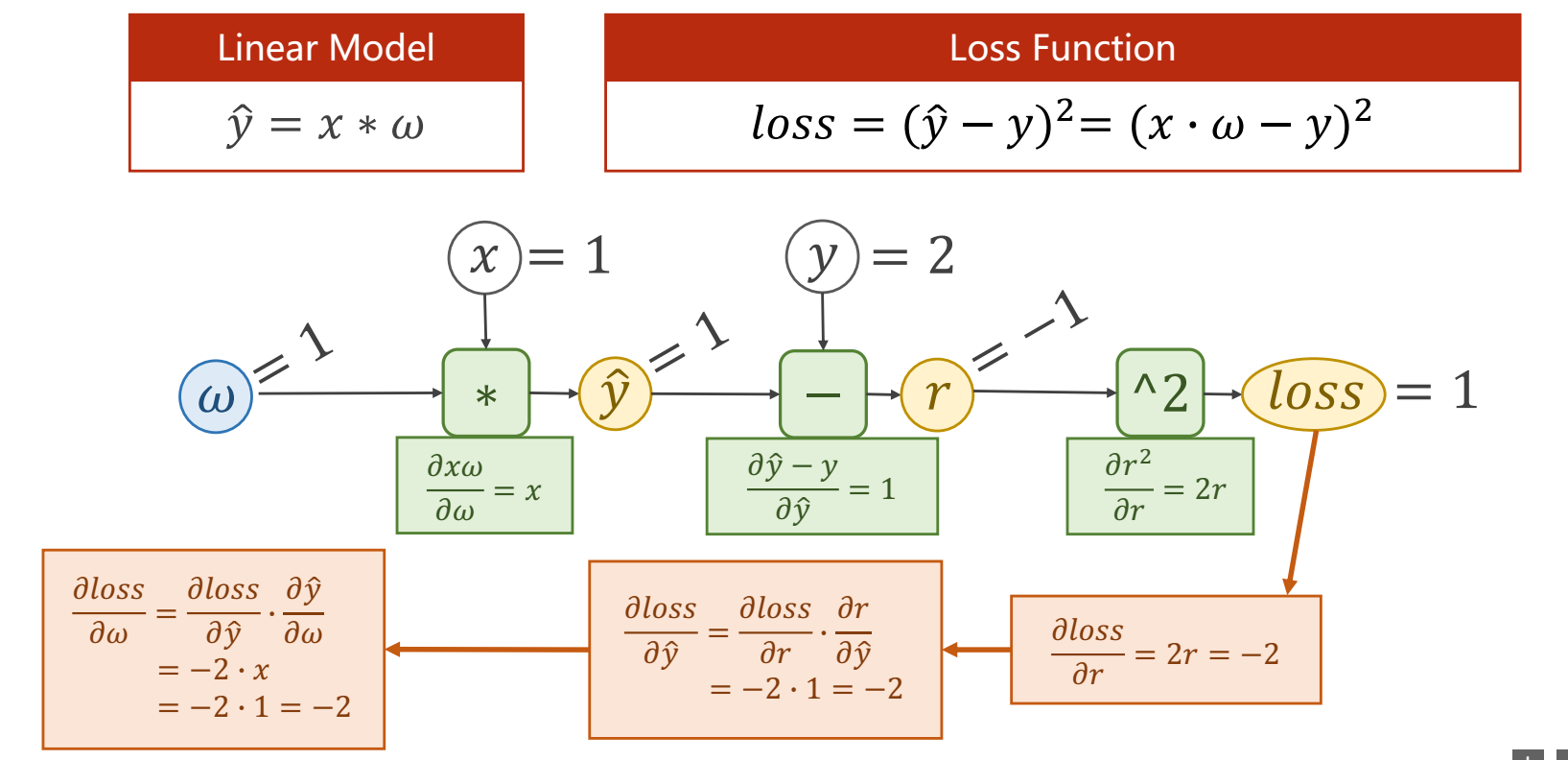
Gradient Descent
x_data = [1,2,3]
y_data = [2,4,6]
w=1
def forward(x):
return x*w
def loss(xs,ys):
loss = 0
for x,y in zip(xs,ys):
y_pred = forward(x)
loss += (y_pred-y)**2
return loss/len(xs)
def gradient(xs,ys):
grad=0
for x,y in zip(xs,ys):
grad += 2*x*(x*w-y)
return grad/len(xs)
print('Predict(before training)',4, forward(4))
for epoch in range(100):
loss_val = loss(x_data, y_data)
grad_val = gradient(x_data, y_data)
w -= 0.01*grad_val
print('Epoch:', epoch, 'w=',w,'loss=',loss_val)
print('Predict(After training)',4, forward(4))
- 随机梯度下降的计算无法并行,计算中是有依赖的
- 随机梯度下降的性能更好,但是无法并行,所以速度比较慢
- 所以我们用mini-batch,批量随机梯度下降,这是一种折中的方法
前向传播和反向传播
02. Linear Model
Tensor & Linear Model
In PyTorch, Tensor is the important component in constructing dynamic computational graph. It contains data and grad, which storage the value of node and gradient w.r.t loss respectively. 如下代码是在构造计算图,在Pytorch中我们需要这样看待它。
import torch
x_data = [1,2,3]
y_data = [2,4,6]
w = torch.Tensor([1.0])
w.requires_grad = True
def forward(x):
return x * w
def loss(x,y):
y_pred = forward(x)
return (y_pred-y) ** 2
训练过程
sum = 0
for epoch in range(100):
for x, y in zip(x_data, y_data): # 抽取样本
l = loss(x, y) # 前馈:计算loss,计算完释放
l.backward() # 反馈
print('\tgrad:', x, y, w.grad.item()) #item是一个标量
w.data = w.data - 0.01 * w.grad.data # 注意此时grad要取到data
sum += l.item() # 计算损失和
w.grad.data.zero_() # 清零梯度
print("progress:", epoch, l.item())
NOTICE:
The grad computed by .backward() will be accumulated. So after update, remember set the grad to ZERO!!
.data返回的是一个Tensor,而.item()返回的是具体的数值(非Tensor数据类型)。
Framework
4个步骤:
Prepare dataset : we shall talk about this later
Design model using Class: inherit from nn.Module
Construct loss and optimizer: using PyTorch API
Training cycle: forward, backward, update
Prepare dataset
In PyTorch, the computational graph is in mini-batch fashion, so X and Y are $3 \times 1$ Tensors.
$$\hat{y}=w\cdot x+b$$ $$\left[\begin{aligned}&y_{pred}^{(1)}\\ &y_{pred}^{(2)} \\ &y_{pred}^{(3)} \end{aligned}\right]=w\cdot \left[\begin{aligned}&x^{(1)}\\ &x^{(2)} \\ &x^{(3)}\end{aligned}\right]+b$$
import torch
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[2.0], [4.0], [6.0]])
Design Model
class LinearModel(torch.nn.Module):
def __init__(self): # 构造函数
super(LinearModel, self).__init__() # 调用父类的构造
self.linear = torch.nn.Linear(1,1) # 构造对象
def forward(self, x): # 必须有forward传播函数的定义
y_pred = self.linear(x)
return y_pred
model = LinearModel()
nn.Linearcontain two member Tensors: weight and bias
class torch.nn.Linear(in_features, out_features, bias = True)Applies a linear transformation $y=Ax+b$ Parameters:
- in_features: the size of each input sample
- out_features: the size of each output sample
- bias: Default: True
实际上,在运算过程中是做转置的 $$y=x\cdot w+b$$ $$y = w^{T}\cdot x+b$$
Construct Loss and Optimizer
criterion = torch.nn.MSELoss(size_average=False)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
class torch.nn.MSELoss(size_average, reduce = True)求均方根值 $l(x,y)=L={l_1,\cdots,l_N}^{T},\quad l_n=(x_n-y_n)^2$ 其中,N是batch size。
class torch.optim.SGD(params, lr=<object object>, momentum = 0, dampening = 0, weight_decay = 0, nesterov = False)
Implements stochastic gradient descent (optionally with momentum)
Training Cycle
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss)
optimizer.zero_grad() # 注意梯度清零
loss.backward() # 反向传播
optimizer.step() #Update
Test Model
# Output weight and bias
print('w=', model.linear.weight.item())
print('b=', model.linear.bias.item())
# Test Model
x_test = torch.Tensor([4.0])
y_test = model(x_test)
print('y_pred=', y_test.data)
03. Logistic Regression
One Dimension
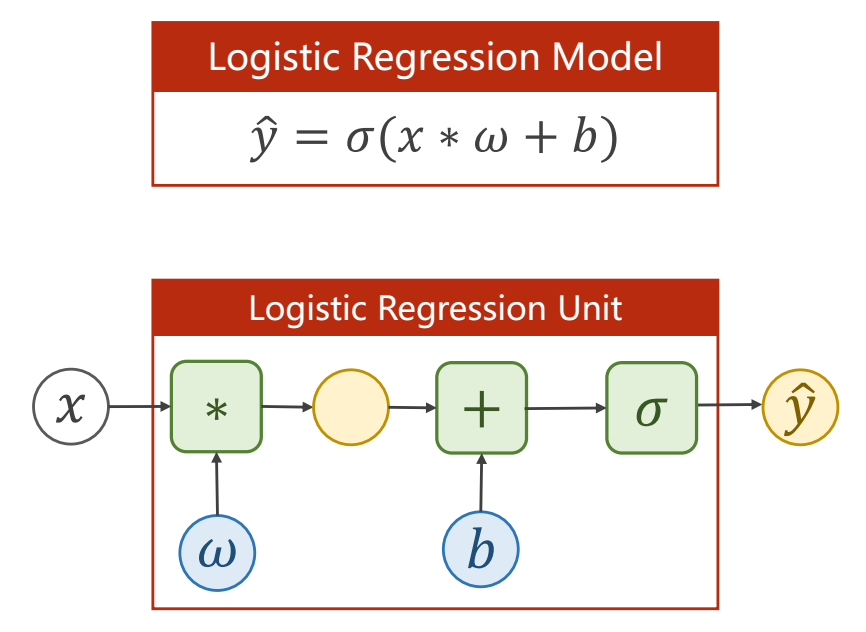 Logistic function can guarantee that the output is in $[0,1]$, and loss function is $$loss=-(y\log \hat{y}+(1-y)\log (1-\hat{y}))$$
此时误差计算的是分布的差异 (BCE),而不是几何上的距离。
Logistic function can guarantee that the output is in $[0,1]$, and loss function is $$loss=-(y\log \hat{y}+(1-y)\log (1-\hat{y}))$$
此时误差计算的是分布的差异 (BCE),而不是几何上的距离。
Mini-Batch Loss Function for Binary Classification $$loss=-\frac{1}{N}\sum^N_{n=1}(y_n\log \hat{y}_n+(1-y_n)\log (1-\hat{y}_n))$$
流程和之前的差不多,代码如下:
#---------------------Prepare dataset--------------------------#
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[0], [0], [1]])
#-----------------Design model using Class---------------------#
class LogisticRegressionModel(torch.nn.Module):
def __init__(self):
super(LogisticRegressionModel, self).__init__()
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
y_pred = F.sigmoid(self.linear(x))
return y_pred
model = LogisticRegressionModel()
#----------------Construct loss and optimizer------------------#
criterion = torch.nn.BCELoss(size_average=False)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
#----------------------Training cycle--------------------------#
for epoch in range(1000):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
Multi Dimension
二维数据中,一般来说列对应的是feature,行对应的是sample,一行为一条record
Mini-Batch(N samples)
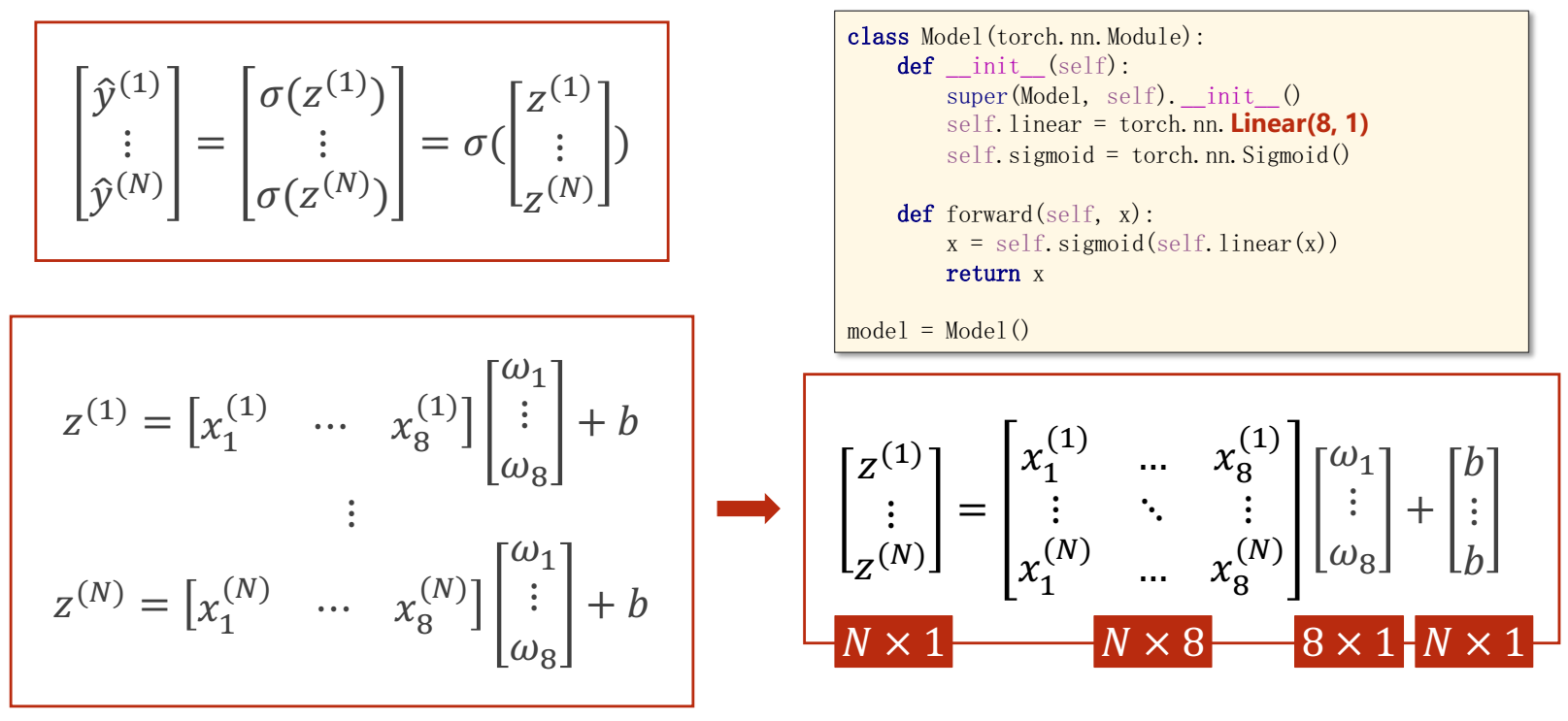
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear = torch.nn.Linear(8, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear(x))
return x
model = Model()
Prepare Dataset
import numpy as np
xy = np.loadtxt('diabetes.csv.gz', delimiter=',', dtype=np.float32)
x_data = torch.from_numpy(xy[:,:-1]) # 除了最后一行都要
y_data = torch.from_numpy(xy[:, [-1]])
Define Model
import torch
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
Construct Loss and Optimizer
criterion = torch.nn.BCELoss(size_average=True)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
Training Cycle
for epoch in range(100):
# Forward
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
# Backward
optimizer.zero_grad()
loss.backward()
# Update
optimizer.step()
04. Dataset and DataLoader
Use all of the data
xy = np.loadtxt(‘diabetes.csv.gz’ , delimiter=‘,’ , dtype=np.float32)
x_data = torch.from_numpy(xy[:,:-1])
y_data = torch.from_numpy(xy[:, [-1]])
……
for epoch in range(100):
# 1. Forward
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
# 2. Backward
optimizer.zero_grad()
loss.backward()
# 3. Update
optimizer.step()
Terminology
# Training cycle
for epoch in range(training_epochs):
# Loop over all batches
for i in range(total_batch):
- Epoch One forward pass and one backward pass of all the training examples.
- Batch-Size The number of training examples in one forward backward pass.
- Iteration Number of passes, each pass using batch size number of examples.
比如,1000个样本,我们分成10个Batch,Batch-Size=100,Iteration=10
DataLoader
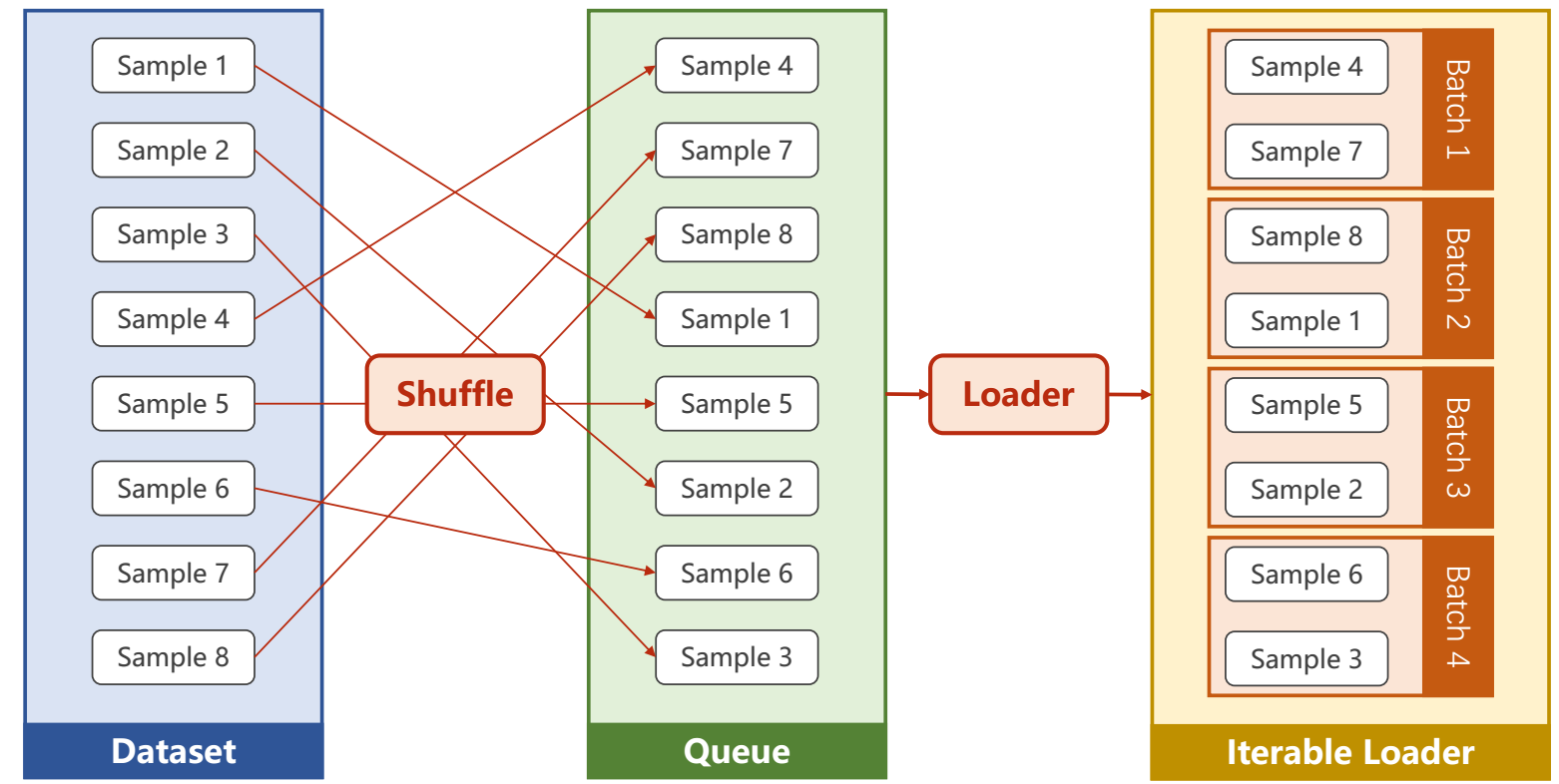
Define Dataset
- Dataset 是一个抽象类,不可以实例化;而 DataLoader 是可以实例化的
- number workers 指的是多线程并行的个数,好像 Windows 上必须是0,建议在 Linux 使用
- getitem 是当数据比较大,需要通过读取文件名来 get 相应的 item 进行处理
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
class DiabetesDataset(Dataset):
def __init__(self):
pass
def __getitem__(self, index):
pass
def __len__(self):
pass
dataset = DiabetesDataset()
train_loader = DataLoader(dataset=dataset,
batch_size=32,
shuffle=True,
num_workers=2)
for epoch in range(100):
for i, data in enumerate(train_loader, 0):
……
Example: Diabetes Dataset
class DiabetesDataset(Dataset):
def __init__(self, filepath):
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)
self.len = xy.shape[0] # 取第0元素:长度
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
def __getitem__(self, index):
return self.x_data[index], self.y_data[index] # 返回对应样本即可
def __len__(self):
return self.len
dataset = DiabetesDataset('diabetes.csv.gz')
train_loader = DataLoader(dataset=dataset,
batch_size=32,
shuffle=True,
num_workers=2)
for epoch in range(100):
for i, data in enumerate(train_loader, 0):
# 1. Prepare data
inputs, labels = data
# 2. Forward
y_pred = model(inputs)
loss = criterion(y_pred, labels)
print(epoch, i, loss.item())
# 3. Backward
optimizer.zero_grad()
loss.backward()
# 4. Update
optimizer.step()
- i代表的是第几组数据,表示每次拿的是 $x[i],y[i]$
- train_loader 拿出来的是一个元组 $(X,Y)$,是 getitem 传过来的
- 0代表是从第0个开始枚举
- inputs代表 x,labels代表y。或者我们可以将data改为 (input,labels)
05. Softmax
Softmax概念
对于多输出,我们要对输出进行进一步的规格化 $$P(y=i)\ge 0\qquad \sum_{i=0}^9 P(y=i)=1$$ Suppose $𝑍^𝑙 ∈ ℝ^𝐾$ is the output of the last linear layer, the* Softmax function*: $$P(y=i)=\frac{e^{z_i}}{\sum_{j=0}^{K-1} e^{z_j}},\quad i\in {0,\cdots ,K-1}$$
import torch
criterion = torch.nn.CrossEntropyLoss()
Y = torch.LongTensor([2, 0, 1])
Y_pred1 = torch.Tensor([[0.1, 0.2, 0.9],
[1.1, 0.1, 0.2],
[0.2, 2.1, 0.1]])
Y_pred2 = torch.Tensor([[0.8, 0.2, 0.3],
[0.2, 0.3, 0.5],
[0.2, 0.2, 0.5]])
l1 = criterion(Y_pred1, Y)
l2 = criterion(Y_pred2, Y)
print("Batch Loss1 = ", l1.data, "\nBatch Loss2=", l2.data)
CrossEntropyLoss vs NULLoss
Implementation
Package
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
transform: 对数据集进行处理F: For using function relu()optim: For constructing Optimizer
Prepare Dataset
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307, ), (0.3081, ))
])
train_dataset = datasets.MNIST(root='../dataset/mnist/',
train=True,
download=True,
transform=transform)
train_loader = DataLoader(train_dataset,
shuffle=True,
batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/',
train=False,
download=True,
transform=transform)
test_loader = DataLoader(test_dataset,
shuffle=False,
batch_size=batch_size)
- transform是为了Normalization数据,0.1307是均值,0.3081是标准差。这是MNIST数据集经过计算所得到的均值和标准差。
Design Model
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 784)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x)
model = Net()
Construct Loss and Optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
Train and Test
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad()
# forward + backward + update
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy on test set: %d %%' % (100 * correct / total))
for epoch in range(10):
train(epoch)
test()
MENTION
我们在打标签的时候需要从0开始,否则是有问题的。
06. CNN
卷积神经网络可以做到保留原始的空间信息,而全连接层是展开成一个,无法保留空间信息。
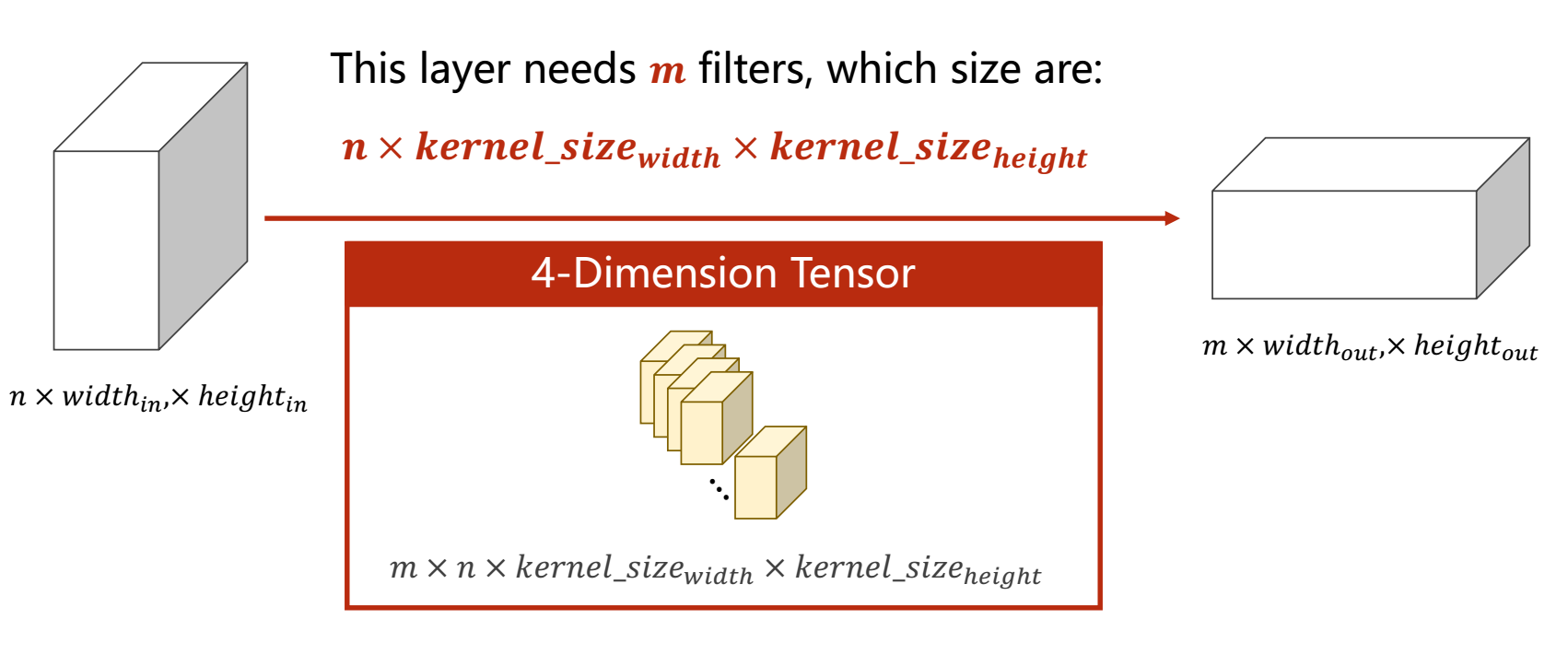
import torch
in_channels, out_channels= 5, 10
width, height = 100, 100
kernel_size = 3
batch_size = 1
input = torch.randn(batch_size,
in_channels,
width,
height)
conv_layer = torch.nn.Conv2d(in_channels,
out_channels,
kernel_size=kernel_size)
output = conv_layer(input)
print(input.shape)
print(output.shape)
print(conv_layer.weight.shape)
输出为:
torch.Size([1, 5, 100, 100])
torch.Size([1, 10, 98, 98])
torch.Size([10, 5, 3, 3])
MNIST Example

Move Model to GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
# forward + backward + update
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 2000))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, dim=1)
total += target.size(0)
correct += (predicted == target).sum().item()
print('Accuracy on test set: %d %% [%d/%d]' % (100 * correct / total, correct, total))
Inception Module
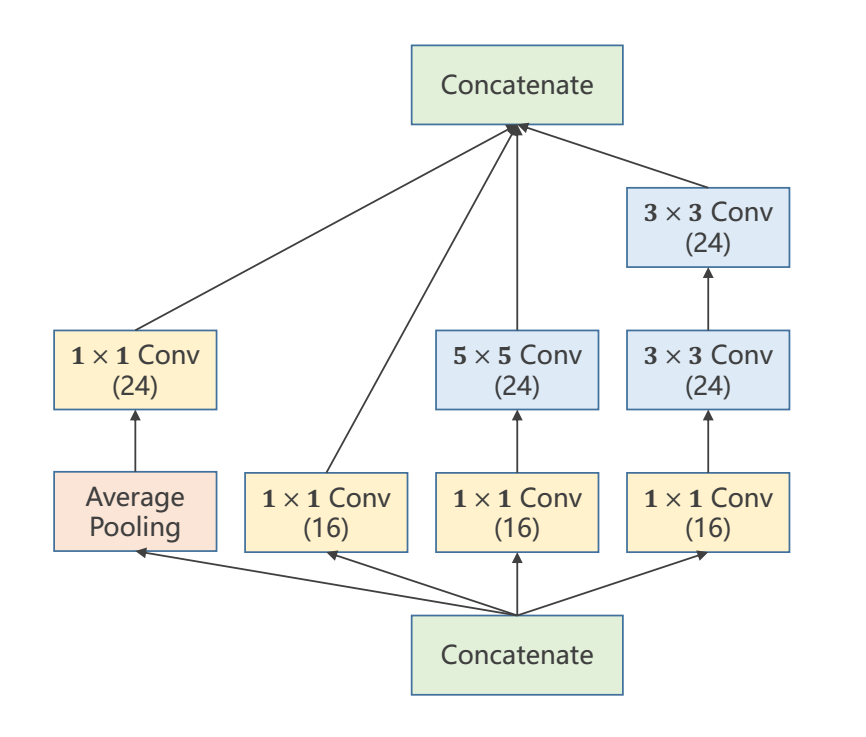
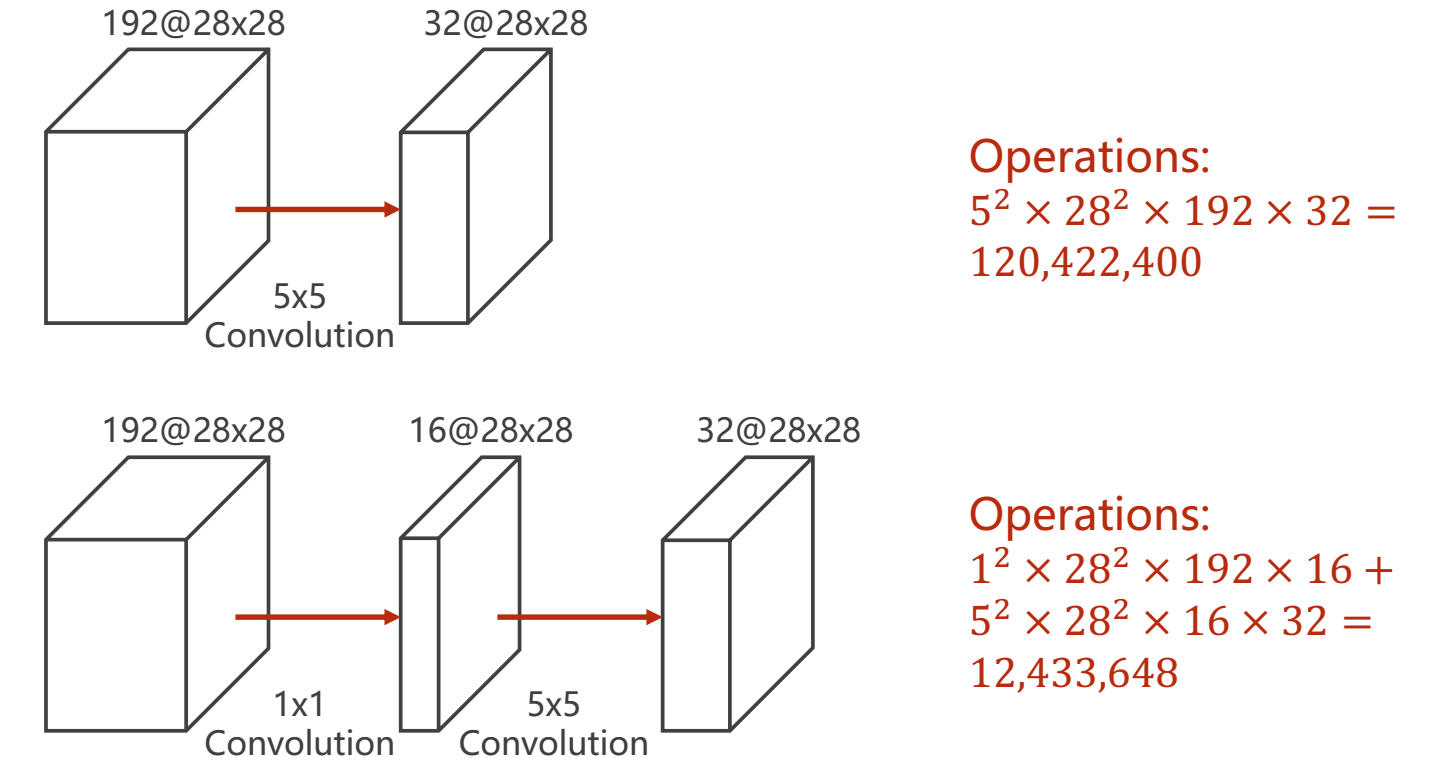
1x1 convolution
可以改变通道数量,可以跨越不同通道相同像素的值,做到了信息融合的目的。 卷积核的数量就代表了通道的数量。 作用:降低运算量